
Zaman Serisi Verisi: Timescale/TSDB Yaklaşımıyla SCADA Verisi Nasıl Saklanır? (Partition, Retention, Sorgu Performansı)

Enerji tesislerinde gerçek zamanlı izleme büyüdükçe, “veriyi topluyor muyuz?” sorusu hızla “bu veriyi yıllarca nasıl saklarız ve hâlâ hızlı sorgularız?” sorusuna dönüşür. SCADA tarafında saniyelik (hatta daha sık) telemetri; kW, debi, kapak, titreşim, sıcaklık gibi yüzlerce–binlerce tag üzerinden sürekli akar. Birkaç ay içinde satır sayısı milyar seviyelerine yaklaşabilir. Bu noktada klasik ilişkilisel tablo tasarımıyla devam etmek; indeks şişmesi, sorgu gecikmeleri, maliyet artışı ve bakım zorluğu ile sonuçlanır.
Bu yazıda, zaman serisi verisi (time-series) için TSDB yaklaşımını ve Postgres ekosisteminde öne çıkan Timescale benzeri “hypertable + chunk” modelini SCADA bağlamında anlatacağız. Amaç; hem gerçek zamanlı panoları milisaniye–saniye düzeyinde hızlı tutmak, hem de yıllık arşivi yönetilebilir maliyetle saklamak. Bunun için partition/chunk stratejisi, retention politikaları, downsampling (özet veri), sık sorgu tipleri ve performans/operasyon pratiklerini bir bütün olarak ele alacağız.
1) TL;DR
- SCADA verisi “yüksek hacimli yazma + zaman aralığı sorguları” problemidir; zaman bazlı bölümlendirme (partition/chunk) şarttır [1][2].
- “Her şeyi ham veri olarak sonsuza kadar tutmak” sürdürülemez; retention + downsampling ile “ham veri kısa, özet veri uzun” piramidi kurulmalıdır [3][4].
- Doğru indeksler ve doğru chunk/partition boyu; hem yazma hızını hem de sorgu gecikmesini belirler. PostgreSQL’in declarative partitioning yaklaşımı bu temel mantığı sağlar [2].
- Sorguların büyük bölümü birkaç paterne indirgenir: son X dakika trendi, belirli zaman aralığında agregasyon, alarm sonrası inceleme, dashboard KPI. TSDB tasarımı bu paternlere göre yapılmalıdır.
- Zaman serisi verisinin etkin yönetimi için veri toplama, bağlam etiketleme, anomali analizi ve sorgu optimizasyonunun tek bir mimari içinde ele alınması gerekir.
2) Kavramlar ve teorik arka plan
2.1 Zaman serisi (time-series) verisi nedir?
Zaman serisi verisi; her kaydın bir zaman damgası (timestamp) taşıdığı, genellikle sensör/ölçüm akışı şeklinde oluşan veridir. SCADA’da bu, tag bazlı ölçümler (kW, debi, titreşim RMS vb.) olarak karşımıza çıkar. Temel özellikler şunlardır:
- Yazma yoğunluğu yüksektir (append-only eğilim).
- Sorgular çoğunlukla zaman aralığına dayanır (last 15 min, today, last 30 days).
- Agregasyon çok sık kullanılır (ortalama, max, min, percentiles, rollup).
- “Cardinality” (tag sayısı ve etiket kombinasyonları) büyüdükçe maliyet artar.
2.2 TSDB yaklaşımı neden gerekir?
Klasik ilişkisel modelde tek büyük tablo + indeksler, zamanla ağırlaşır. Zaman serisi için pratik çözüm; veriyi zaman eksenine göre doğal olarak bölmek (partition) ve “eski veriyi” arşiv/özet seviyesine indirmektir. PostgreSQL, declarative partitioning ile tabloları parçalara ayırmayı destekler [2]. Timescale benzeri TSDB yaklaşımlarında ise bu parçalar genellikle “chunk” olarak otomatik yönetilir; zaman aralığına göre yeni chunk’lar açılır ve sorgu, ilgili chunk’lara yönlendirilir [1].
Teknik Not: Hypertable + Chunk Mantığı
- Hypertable: Mantıksal olarak tek tablo gibi görünen, fiziksel olarak zaman aralıklarına bölünmüş yapı.
- Chunk interval: Her parçanın kapsadığı zaman dilimi (ör. 1 gün, 7 gün).
- Amaç: Yazmayı paralelize etmek, eski veriye erişimi filtrelemek ve bakım işlemlerini (compression/retention) chunk bazında çalıştırmak [1].
(Kaynak: [1])
3) Nasıl çalışır? TSDB tasarımının yapı taşları
3.1 Veri modelleme: “narrow” mı “wide” mı?
SCADA’da iki temel şema yaklaşımı vardır:
- A) Narrow (ölçüm tablosu): (time, tag_id, value, quality, status)
- B) Wide (satırda çok kolon): (time, kW, debi, kapak, titreşim, …)
Pratikte SCADA tag sayısı büyüdükçe “wide” yapı yönetilemez hâle gelir. Narrow yapı; yeni tag eklemeyi kolaylaştırır ve zaman serisi iş yüküne daha uygundur. Bunun bedeli; doğru indeks ve doğru partition/chunk ayarı gerektirmesidir. Timescale ekosisteminde “tek hypertable mı, çoklu tablo mu?” gibi modelleme kararları da bu nedenle önemlidir [5].
3.2 Partition/Chunk stratejisi
Zaman bazlı bölümlendirme (partitioning), sorgu performansının temelidir. PostgreSQL’de partitioning, tabloyu partition key’e göre parçalara böler ve “partition pruning” ile gereksiz parçalar sorgu dışı bırakılabilir [2]. Timescale dokümantasyonunda chunk interval mantığı; zaman serisinin otomatik chunk’lara ayrılması şeklinde açıklanır [1].
Chunk/partition boyunu nasıl seçeriz?
- Çok küçük parça: Çok fazla chunk → metadata/bakım maliyeti.
- Çok büyük parça: Sorgu taraması artar → gecikme yükselir.
SCADA’da tipik pratik: ham veride 1 gün–7 gün chunk, özet veride daha büyük aralıklar.
3.3 Retention: “ne kadar saklayacağız?”
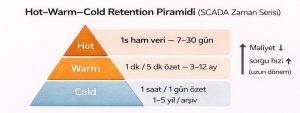
SCADA verisini sonsuza kadar ham tutmak maliyetlidir. TSDB yaklaşımı genellikle “hot–warm–cold” piramidi uygular:
- Hot: saniyelik ham veri (7–30 gün)
- Warm: 1 dk / 5 dk özet (3–12 ay)
- Cold: 1 saat / 1 gün özet (1–5 yıl veya arşiv)
InfluxDB dokümantasyonu, retention policy ve continuous queries ile downsampling + expiry (eskitme) modelini net şekilde anlatır [3][4]. Bu fikir Timescale tarafında da continuous aggregate + retention/compression politikalarıyla benzer şekilde uygulanır; hypertable/continuous aggregate üzerinde politika tanımlanabilir [6].
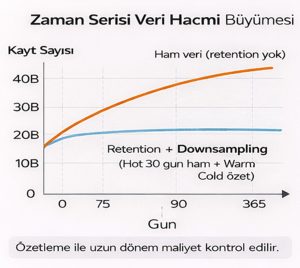
3.4 Downsampling: “ham veriyi özetle”
Downsampling, eski ham veriyi daha düşük çözünürlükte özet veriye dönüştürmektir. Örneğin:
- 1 saniyelik ham → 1 dakikalık ortalama/max/min
- 1 dakikalık → 1 saatlik ortalama + percentiles
Bu sayede:
- Dashboard sorguları hızlanır (daha az satır).
- Depolama maliyeti düşer.
- Uzun dönem trendler okunabilir olur.
3.5 Compression: “eski chunk’ları sıkıştır”
Zaman serisinde veri çoğunlukla append-only olduğu için “eski veri” çok değişmez. Bu, sıkıştırma için idealdir. Timescale ekosisteminde hypertable’larda compression ve compression policy gibi mekanizmalarla eski chunk’lar otomatik sıkıştırılabilir [6].
Risk Kutusu: TSDB Tasarımında En Sık Hatalar
- Ham veriyi sınırsız tutmak (maliyet patlar).
- Cardinality’yi kontrol etmemek (tag/label patlaması).
- Chunk interval’i rastgele seçmek (ya çok küçük ya çok büyük).
- İndeksleri “her şeye” basmak (yazma performansı düşer).
- Zaman senkronizasyonu (NTP/PTP) olmadan veri toplamak (tarih kaymaları).
(Kaynak dayanağı: partition/retention prensipleri [2][3][4])
4) SCADA sorgu tipleri: Tasarımı belirleyen 4 ana kullanım
4.1 “Son X dakika” gerçek zamanlı trend
Operatör ekranları ve alarm panoları genelde son 5–30 dakikayı çeker. Bu sorgular için:
- İndeks: (tag_id, time DESC) veya time odaklı indeks
- Chunk: küçük ama aşırı küçük olmayan aralık (1 gün iyi başlangıç)
- Cache: dashboard katmanında kısa süreli cache
4.2 “Belirli zaman aralığında agregasyon”
Enerji tesislerinde KPI (ortalama güç, günlük debi, max titreşim) için tipik sorgu paterni:
- WHERE time BETWEEN …
- GROUP BY time_bucket(…) / date_trunc(…)
Bu noktada downsampling/continuous aggregate büyük fark yaratır.
4.3 “Alarm sonrası adli inceleme”
Alarmdan önce/sonra 10–30 dakikalık pencerede çoklu tag korelasyonu istenir. Bu sorgular:
- Çok tag → yüksek cardinality
- Zaman penceresi dar → doğru indeks çok kritik
Bu kullanım için “tag grupları” (ünite bazlı) ve sorgu optimizasyonu önemlidir.
4.4 “Uzun dönem raporlama ve karşılaştırma”
Aylık–yıllık raporlarda ham veri yerine özet tablolardan okumak gerekir. Aksi takdirde milyarlarca satır taranır. Retention + downsampling piramidi bu yüzden zorunludur [3][4].
5) Örnek senaryo: HES’te TSDB tasarımını adım adım kurmak
Varsayım:
- 1.500 tag
- Ortalama 1 saniyede 1 ölçüm/tag (1 Hz)
- Günlük kayıt ≈ 1.500 × 86.400 = 129.600.000 satır/gün
Bu hacimde tek tablo yaklaşımı hızla zorlanır. TSDB yaklaşımıyla şu plan uygulanabilir:
Adım 1 — Ölçüm şeması (narrow)
measurements(time, tag_id, value, quality)
İndeks: (tag_id, time) ve time bazlı partition/chunk [2].
Adım 2 — Chunk interval seçimi
Ham veride 1 gün chunk (operasyonel sorgular son 30 gün). Mantık: gün bazlı bakım ve pruning kolaylığı.
Adım 3 — Retention planı
- Hot (ham, 1 saniye): 30 gün
- Warm (1 dk özet): 12 ay
- Cold (1 saat özet): 5 yıl
Adım 4 — Downsampling kuralı
30 günden eski ham veriyi silmeden önce, 1 dakikalık ve 1 saatlik özetleri üret.
InfluxDB’nin RP + CQ yaklaşımındaki gibi “önce özetle, sonra expire” mantığı izlenir [3][4].
Adım 5 — Compression
30 günden eski chunk’lar sıkıştırılır; sorgu nadir ama gerektiğinde erişilebilir olur [6].
Şekil 1 — Hot–Warm–Cold retention piramidi (ham veri kısa, özet veri uzun).
Açıklama: Depolama maliyeti kontrol edilirken raporlama performansı korunur.
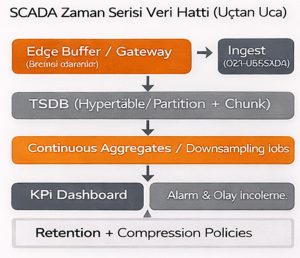
Şekil 2 — SCADA ölçüm hattı: Edge buffer → TSDB ingest → Continuous aggregates → Dashboard/Alarm ekranı.
Açıklama: Kesinti senaryosunda veri kaybını azaltan mimari akışı gösterir.
6) Kurumsal Yaklaşım: SCADA Zaman Serisini Bir Sistem Olarak Yönetmek
SCADA zaman serisi verisi yalnızca depolanan bir veri değil; operasyonel kararları besleyen aktif bir sistem olarak ele alınmalıdır.
1) Veri katmanı (ingest + kalite)
- OPC UA/SCADA entegrasyonu ile tag akışı
- Zaman damgası standartlaştırma (NTP/PTP)
- Kalite bayrakları (quality) ile “güvenilir ölçüm” ayrımı
2) TSDB katmanı (performans + maliyet)
- Hypertable/chunk veya PostgreSQL partitioning mantığıyla zaman bazlı bölümlendirme [1][2]
- Retention + downsampling planı (hot–warm–cold) [3][4]
- Sıkıştırma ve arşiv politikaları [6]
3) Ürün katmanı (operasyonel değer)
- KPI dashboard (kW, debi, verim, titreşim trendleri)
- Alarm ekranları ve olay inceleme
- Bakım/arıza analitiği için özellik çıkarımı (feature store mantığı)
7) Bilgi Kartı: “TSDB tasarım kontrol listesi”
- Zaman senkronizasyonu var mı (NTP/PTP)?
- Tag envanteri ve cardinality kontrol ediliyor mu?
- Chunk/partition interval seçimi test edildi mi?
- Retention piramidi tanımlı mı (hot–warm–cold)?
- Downsampling job/continuous aggregate var mı?
- İndeksler sorgu paternlerine göre mi?
- Backfill ve kesinti senaryosu planlandı mı?
- İzleme: yazma hızı, disk, sorgu gecikmesi, bloat ölçülüyor mu?
(Kaynak: partitioning ve retention prensipleri [2][3][4])
8) Sık sorulan sorular (FAQ)
1) Timescale/TSDB kullanmak zorunlu mu?
Zorunlu değil; ancak saniyelik SCADA akışında zaman bazlı partitioning ve retention planı olmadan sürdürülebilir performans sağlamak zordur [2][3].
2) Chunk interval’i kaç olmalı?
Tek doğru yok. Ham veri için 1 gün–7 gün aralığı yaygındır. En doğru seçim; yazma hızı, sorgu paternleri ve bakım maliyeti ile test edilerek belirlenir [1][2].
3) Ham veriyi kaç gün tutmalıyım?
Operasyonel ihtiyaç belirler. Saha pratiklerinde 7–30 gün ham, daha uzun dönem için özet veri yaklaşımı yaygındır [3][4].
4) Downsampling neyi bozabilir?
Yanlış agregasyon seçilirse kısa süreli pikler kaybolabilir. Bu yüzden max/min ve percentiles gibi özetleri de saklamak gerekir.
5) “Bad actor” (gürültülü tag) TSDB’yi etkiler mi?
Evet. Çok sık değişen veya hatalı sensörler yazma hacmini artırır; hem depolamayı hem de sorguyu etkiler. Bu tag’ler için ayrı izleme ve kalite kontrolleri önerilir.
6) SCADA verisini buluta taşırken en kritik risk nedir?
Zaman senkronizasyonu, veri bütünlüğü ve OT güvenliği (segmentasyon, yetkilendirme, loglama) birlikte ele alınmalıdır [7].
7) PostgreSQL partitioning yeterli mi, özel TSDB şart mı?
PostgreSQL partitioning güçlü bir temeldir [2]. TSDB çözümleri ise otomasyon (chunk yönetimi, sıkıştırma, continuous aggregates) sağlayarak operasyon yükünü azaltabilir [1][6].
9) Sonuç
SCADA zaman serisi verisi, büyüdükçe klasik tablo yaklaşımını zorlayan bir iş yüküne dönüşür. Çözüm; zaman bazlı bölümlendirme (partition/chunk), retention planı ve downsampling piramidini birlikte tasarlamaktır. Bu üçlü; hem gerçek zamanlı panoları hızlı tutar, hem de yıllık arşiv maliyetini kontrol eder [2][3][4].
Uygulanabilir bir sonraki adım:
1) Tag envanterinizi çıkarın ve günlük satır hacmini hesaplayın.
2) Hot–warm–cold retention hedeflerini belirleyin.
3) Ham veride chunk/partition interval’i seçip bir pilot tabloda test edin.
4) 1 dk ve 1 saat özet tablolarını (downsampling) devreye alın.
5) KPI panoları ve alarm ekranlarındaki sorgu paternlerine göre indeks ve özet stratejisini hizalayın.
Bu konuda daha fazla bilgi almak için bizimle iletişime geçebilirsiniz:
Kaynakça
[1] TigerData (Timescale). Hypertables documentation. 2025. (https://www.tigerdata.com/docs/use-timescale/latest/hypertables) Erişim: 2026-02-22
[2] PostgreSQL Global Development Group. Table Partitioning (DDL Partitioning). 2025. (https://www.postgresql.org/docs/current/ddl-partitioning.html) Erişim: 2026-02-22
[3] InfluxData. Downsampling and Data Retention (InfluxDB documentation). 2016. (https://archive.docs.influxdata.com/influxdb/v1.0/guides/downsampling_and_retention/) Erişim: 2026-02-22
[4] InfluxData. Downsampling and Data Retention (InfluxDB documentation). 2015. (https://archive.docs.influxdata.com/influxdb/v0.11/guides/downsampling_and_retention/) Erişim: 2026-02-22
[5] TigerData (Timescale). Best Practices for Time-Series Data Modeling (hypertables vs multiple tables). 2024. (https://www.tigerdata.com/learn/best-practices-time-series-data-modeling-single-or-multiple-partitioned-tables-aka-hypertables) Erişim: 2026-02-22
[6] TigerData (Timescale). add_compression_policy() documentation. 2025. (https://www.tigerdata.com/docs/api/latest/compression/add_compression_policy) Erişim: 2026-02-22
[7] Stouffer, K. et al. NIST SP 800-82 Rev. 3 — Guide to Operational Technology (OT) Security. 2023. (https://csrc.nist.gov/pubs/sp/800/82/r3/final) Erişim: 2026-02-22